マルコフ決定過程
マルコフ決定過程(マルコフけっていかてい、英: Markov decision process; MDP)は、状態遷移が確率的に生じる動的システム(確率システム)の確率モデルであり、状態遷移がマルコフ性を満たすものをいう。 MDP は不確実性を伴う意思決定のモデリングにおける数学的枠組みとして、強化学習など動的計画法が適用される幅広い最適化問題の研究に活用されている。 MDP は少なくとも1950年代には知られていた[1]が、研究の中核は1960年に出版された Ronald A. Howard の "Dynamic Programming and Markov Processes" に起因する[2]。 MDP はロボット工学や自動制御、経済学、製造業を含む幅広い分野で用いられている。
概要
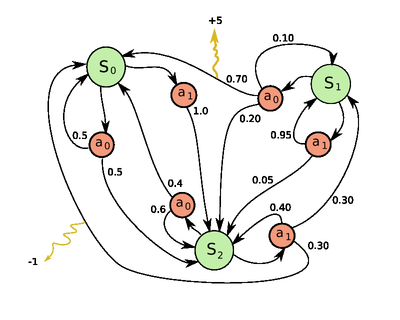
マルコフ決定過程は離散時間における確率制御過程 (stochastic control process) である。 各時刻において過程 (process) はある状態 (state) を取り、意思決定者 (decision maker) はその状態において利用可能な行動 (action) を任意に選択する。 その後過程はランダムに新しい状態へと遷移し、その際に意思決定者は状態遷移に対応した報酬 (reward) を受けとる。
遷移後の状態 、および得られる報酬の値 は現在の状態 と行動 のみに依存し、 と が与えられたもとでそれより過去の状態および行動と条件付き独立となる。 言い換えると、マルコフ決定過程の状態遷移はマルコフ性を満たす。




マルコフ決定過程はマルコフ連鎖に(選択可能な)行動、および(行動を計画する動機を与える)報酬を追加し拡張したものであると解釈できる。 逆に言えば、各ステップにとる行動がそのステップにおける状態のみ依存するとき、マルコフ決定過程は等価なマルコフ連鎖に置き換えることが出来る。
定義
有限マルコフ決定過程 (finite Markov decision process; finite MDP) は4つの要素の組 で表される。ここで各要素はそれぞれ次を意味する。

- : 状態の有限集合
- : 行動の有限集合
- : 遷移関数 (transition function)
- : 報酬関数 (reward function)


![{\displaystyle T:S\times A\times S\to [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/69a2a983071005aecfd5a367d16d492044308fe1)

遷移関数 は状態 にあり行動 を取ったときの状態 への状態遷移確率 である。 また報酬関数 は状態 から に行動 を伴い遷移する際に得られる即時報酬 (immediate reward) 、またはその期待値 を表す。



![{\displaystyle \mathbb {E} [r_{t+1}|s,a,s']}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a52f9346fe5e76c4e71d42662a66b4e20cd87545)
問題設定
MDP における基本的な問題設定は、現在の状態が が与えられたときに意思決定者の取る行動 を既定する方策 (policy) を求めることである。 方策は通常 の条件付き分布 として規定され、状態 に 行動 を取る確率を と表記する。




方策を求める際に用いられるゴール(目的関数)は、典型的には現在時刻から無限区間先の未来までにおける「割引された」報酬の累積値が用いられる:

ここで は割引率 (discount rate) と呼ばれる値であり、現在の報酬と未来の報酬との間における重要度 (importance) の差異を表している。 状態が確率的に遷移することから上の値は確率変数となるため、通常はその期待値が用いられる。
![{\displaystyle \gamma \in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbc65bc4fa0e25a8305259b234865def64ac1a8a)
アルゴリズム
MDP は線形計画法または動的計画法で解くことができる。ここでは後者によるアプローチを示す.
いま,ある(定常な)方策 を採用した場合における割引報酬和 は現在の状態 のみに依存し、これを 状態価値関数 (state-value function) と呼ぶ( は方策 の下での条件付き期待値)。 この状態価値関数 は次式を満たす。

![{\textstyle V^{\pi }(s)=\mathbb {E} _{\pi }[\sum _{t=0}^{\infty }\gamma ^{t}r_{t+1}\ |s_{0}=s]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dcc93e242695f56171870c541b18592604751af3)
![{\displaystyle \mathbb {E} _{\pi }[\cdot ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6af14353fe2ec61ef0125ed7b305b09ce721f9d0)

ただし は状態 において方策 を採用した場合における即時報酬の期待値である。


任意の および に対し を満たす方策 を最適方策 (optimal policy) と呼ぶ。 を採用したときの状態価値関数の最大値 は次のベルマン方程式を満たす[3].






価値反復法
価値反復法 (value iteration)[1]は後ろ向き帰納法 (backward induction) とも呼ばれ、ベルマン方程式を満たす価値関数を繰り返し計算により求める。 ロイド・シャープレー が1953年に発表した確率ゲーム(英語版)に関する論文[4]には価値反復法の特殊な場合が含まれるが、このことが認知されたのは後になってからである[5].
ステップ における価値関数の計算結果を と表記すると、価値反復法における更新式はつぎのように記述される:



上式をすべての状態において値が収束するまで繰り返したときの値を とし、最適方策 を次式で求める。


方策反復法
方策反復法 (policy iteration)[2]では、方策固定の下で行われる価値関数の更新 (policy evaluation) と、価値関数固定のもとで行われる方策の更新 (policy improvement) を交互に行うことで最適方策を求める。
- 次の線形方程式を解き、価値関数を更新する
- 方策を次式で更新する


これらの操作を がすべての状態に対し変化しなくなるまで繰り返すことで、最適方策を得る。 方策反復法は離散値を取る方策の値が変化しなくなるという明確な終了条件を持つため有限時間でアルゴリズムが終了するという利点を持つ。
拡張と一般化
部分観測マルコフ決定過程
「部分観測マルコフ決定過程」も参照
MDP では方策 を計算する際に現在の状態 が既知であることを仮定している。 実際には状態観測に不確実性が伴う場合などこの仮定が成り立たない場合が多く、このような場合の一般化として部分観測マルコフ決定過程 (Partially Observable Markov Decision Process; POMDP) が用いられる。

強化学習
状態遷移確率 や報酬関数 が未知の場合,環境との相互作用を通じてこれらの情報を得ながら行動を決定する必要がしばしば生じる.このような問題は強化学習の枠組みで議論される[6].
強化学習における代表的な学習アルゴリズムはQ学習と呼ばれるものである。 Q学習では、行動価値関数 (action-value function) と呼ばれる関数 に着目する。ここで は次のように定義される:

![{\displaystyle Q^{\pi }(s,a)=\mathbb {E} _{\pi }[\sum _{t=0}^{\infty }\gamma ^{t}r_{t+1}|s_{0}=s,a_{0}=a]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/943a0121f9da52c6bf3e97edd724ec7cd534b178)
いま,最適方策のもとでの行動価値関数 は を満たす。 すなわち、 を学習することができれば(モデルのパラメータを直接求めることなく)最適方策を獲得することができる。 Q学習では、各試行における遷移前後の状態と入力、および試行で得られる即時報酬の実現値をもとに の値を逐次更新する。 実際の学習プロセスでは、すべての状態を十分サンプリングするため確率的なゆらぎを含むよう学習時の行動が選択される。




強化学習では最適化に必要なパラメータの学習を状態遷移確率・報酬関数を介することなくおこなうことが出来る(価値反復法や方策反復法ではそれらの明示的な仕様(各状態間の遷移可能性,報酬関数の関数形など)を与える必要がある)。 状態数(および行動の選択肢)が膨大な場合、強化学習はしばしばニューラルネットワークなどの関数近似と組み合わせられる。
学習オートマトン
機械学習理論における MDP のもう一つの応用は学習オートマトン (Learning Automata) と呼ばれる。 これは環境が確率的な挙動を示す場合における強化学習の一つでもある。 学習オートマトンに関する最初の詳細な論文は 1974 年に Narendra と Thathachar によりまとめられた[7](そこでは有限状態オートマトンと明示的に記載されている)。 強化学習と同様,学習オートマトンのアルゴリズムも確率や報酬が未知の場合の問題を解くことができる。 Q学習の違いは,価値関数ではく学習の結果を探すために行動の確率を直接求めることである。 学習オートマトンは収束性が解析学の要領で厳密に証明されている[8].
制約付きマルコフ決定過程
制約付きマルコフ決定過程 (Constrained Markov Decision Process; CMDP) はマルコフ決定過程の拡張である。 MDP と CMDP には3つの基本的な違いがある[9]:
- ある行動をほかのものの代わりに適用した後で(複数の)コストが発生する
- CMDP は線形計画法のみで解くことが出来る(動的計画法を用いることはできない)
- 終端時刻における方策が初期状態に依存する
CMDP の応用例は数多く存在し、最近ではロボット工学におけるモーションプランニングに用いられている[10]。
参考文献
- Bellman, R. (1957). “A Markovian Decision Process”. Journal of Mathematics and Mechanics 6. http://www.iumj.indiana.edu/IUMJ/FULLTEXT/1957/6/56038.
- Howard, Ronald. A. (1960). Dynamic Programming and Markov Processes. The M.I.T. Press
- Shapley, Lloyd. (1953). “Stochastic Games”. Proceedings of National Academy of Science 39: 1095–1100.
- Kallenberg, Lodewijk. (2002). “Finite state and action MDPs”. Handbook of Markov decision processes: methods and applications. Springer. ISBN 0-7923-7459-2
- Sutton, R. S.; Barto, A. G. (1998). Reinforcement Learning: An Introduction. Cambridge, MA: The MIT Press. http://webdocs.cs.ualberta.ca/~sutton/book/the-book.html
- Narendra, K. S.; Thathachar, M. A. L. (1974). “Learning Automata - A Survey”. IEEE Transactions on Systems, Man, and Cybernetics SMC-4 (4): 323–334. doi:10.1109/TSMC.1974.5408453. ISSN 0018-9472. http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=5408453.
- Narendra, Kumpati S.; Thathachar, Mandayam A. L. (1989). Learning automata: An introduction. Prentice Hall. ISBN 9780134855585. https://books.google.com/books?id=hHVQAAAAMAAJ
- Altman, Eitan (1999). Constrained Markov decision processes. 7. CRC Press
- Feyzabadi, S.; Carpin, S. (2014). "Risk-aware path planning using hierarchical constrained Markov Decision Processes". Automation Science and Engineering (CASE). IEEE International Conference. pp. 297, 303. doi:10.1109/CoASE.2014.6899341。
- 木村, 元 (2013). “《第1回》強化学習の基礎”. 計測と制御 (計測自動制御学会) 52 (1): 72-77. NAID 10031140795. https://doi.org/10.11499/sicejl.52.72.
外部リンク
- Reinforcement Learning An Introduction by Richard S. Sutton and Andrew G. Barto
- Learning to Solve Markovian Decision Processes by Satinder P. Singh
- Optimal Adaptive Policies for Markov Decision Processes by Burnetas and Katehakis (1997)
- ソフトウェアパッケージ
- MDP Toolbox for MATLAB, GNU Octave, Scilab and R The Markov Decision Processes (MDP) Toolbox.
- MDP Toolbox for Matlab - An excellent tutorial and Matlab toolbox for working with MDPs.
- MDP Toolbox for Python A package for solving MDPs
- SPUDD A structured MDP solver for download by Jesse Hoey
関連項目
| |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 確率の歴史 | |||||||||||
| 確率の定義 |
| ||||||||||
| 基礎概念 |
| ||||||||||
| 確率の解釈 | |||||||||||
| 問題 | |||||||||||
| 法則・定理 | |||||||||||
| 測度論 | |||||||||||
| 確率微分方程式 | |||||||||||
| 確率過程 | |||||||||||
| 情報量 | |||||||||||
| 応用 |
| ||||||||||
| | |||||||||||
- 表示
- 編集









